◈ DML ◈
• ORDER BY
SELECT에 의해서 조회된 데이터를 정려해주는 구문으로써, 데이터의 조회 후 실행되기
때문에 SELECT문의 가장 마지막에 실행됨
아래의 옵션은 생략 가능함
• ORDER BY
EMPLOYEE_ID 컬럼을 내림차순으로 정렬

• 그룹함수
여러 개의 행을 묶어 연산하여 결과를 반환하며 자주 쓰이는 그룹 함수는 아래와 같음
* Oracle의 내장함수 중 한가지 분류임. 그룹함수 외에도 문자함수, 수치 함수, 날짜 함수 등의 내장 함수들이 존재함

• 그룹함수 - MAX
EMPLOYEES 테이블에 있는 SALARY 컬럼의 최대 값을 반환

• 그룹함수 - MIN
EMPLOYEES 테이블에 있는 SALARY 컬럼의 최대 값을 반환

• 그룹함수 - AVG
EMPLOYEES 테이블에 있는 SALARY 컬럼의 평균 값을 반환

• 그룹함수 - SUM
EMPLOYEES 테이블에 있는 SALARY 컬럼의 합계 값을 반환

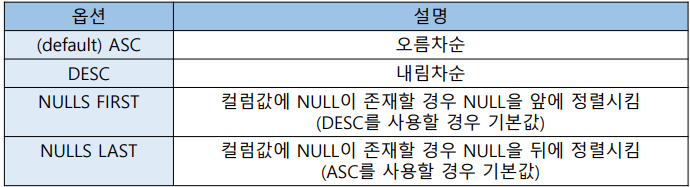
• 그룹함수 - COUNT
EMPLOYEES 테이블에 있는 SALARY 컬럼의 데이터가 조회된 행의 개수를 반환
• GROUP BY
조회된 데이터의 여러 개 행을 특정 컬럼을 기준으로 묶어 그룹화 시키며 일반적으로 그룹 함수와 함께 사용됨
특정 컬럼을 기준으로 그룹화 하여 값을 조회할 수 있음
• WHERE을 사용한다면 GROUP BY 작성 이전에 사용 해야 함
• GROUP BY 이후 조건을 주고 싶다면 이후에 나오는 다른 방식으로 가능
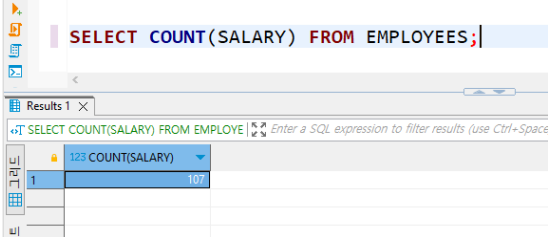
• GROUP BY
EMPLOYEES 테이블에서 DEPARTMENT_ID를 기준으로 그룹화 한 뒤 각 부서별 합계 월급을 조회
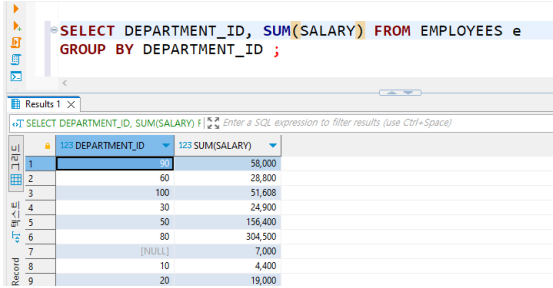
• GROUP BY
EMPLOYEES 테이블에서 DEPARTMENT_ID를 기준으로 그룹화 한 뒤 각 부서별 존재하는 데이터의 행의 개수를 조회(즉, 부서별 직원 수 조회)
• GROUP BY
JOB_ID가 일치하는 직원들의 평균 월급 조회
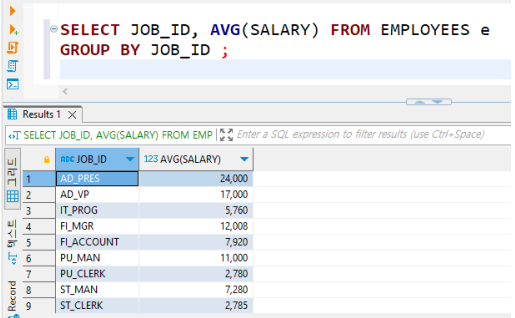
• HAVING
GROUP BY에서 조건을 제시할 때 사용되는 구문
• HAVING(예)
JOB_ID를 기준으로 평균 월급을 구하되 10,000달러 이상인 직원들만 조회
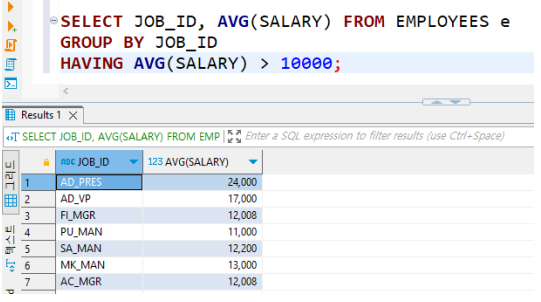
• HAVING(예)
JOB_ID를 기준으로 가장 높은 월급을 조회
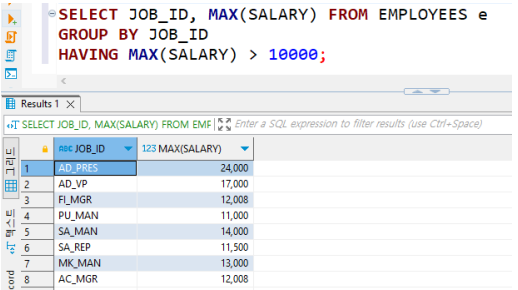
• HAVING(예)
보너스를 받지 않는 JOB_ID 조회
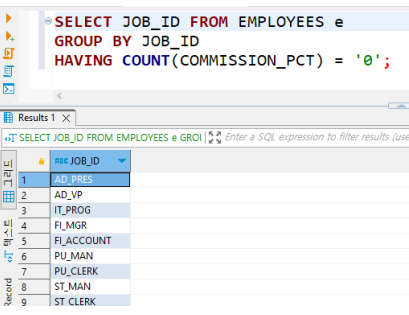
• SELECT 쿼리의 실행 순서
1. FORM 2. WHERE 3. GROUP BY 4. HAVING 5. SELECT 6. ORDER BY
• 실행 순서 예시 쿼리
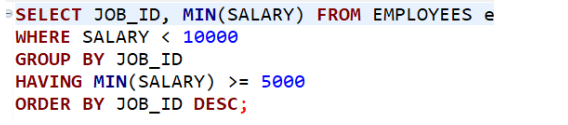
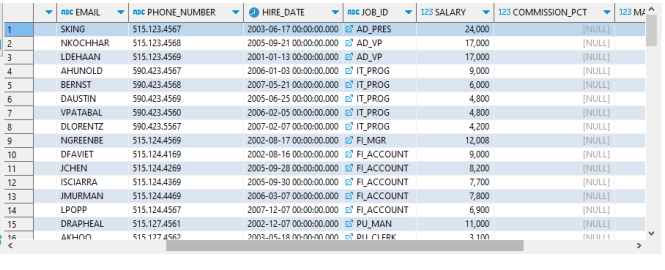
1. FORM
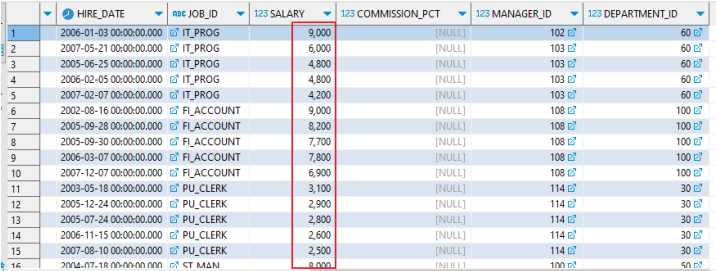
2. WHERE
3. GROUP BY
-> GROUP BY에 작성한 컬럼을 기준으로 각각 그룹화하여 묶음
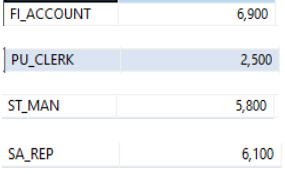
4. HAVING
참고 : 위와 같이 HAVING은 연산이 수행되기 전 이미 GROUP BY와 HAVING 단계를 거치기 때문에 조건을 줄 때 WHERE에서 처리할 수 있는 조건은 WHERE에서 주게되면 불필요한 단계를 거치지 않을 수 있기 때문에 퍼포먼스를 좋게 만들 수 있음
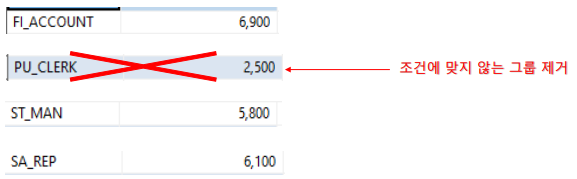
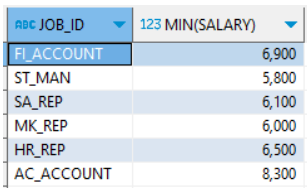
5. SELECT
-> 조건에 충족된 그룹들 묶어 출력할 준비를 하는 단계
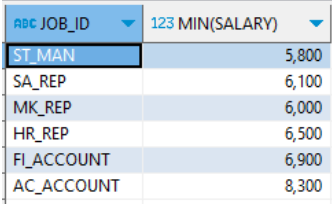
6. ORDER BY
->출력할 데이터들을 정렬
'Back-End > Oracle' 카테고리의 다른 글
| Oracle ■ DML INSERT, UPDATE, DELETE (5) | 2024.07.24 |
|---|---|
| Oracle ■ DML SELECT (4)-서브쿼리 (0) | 2024.07.17 |
| Oracle ■ DML SELECT(3)-집합 연산자,조인 (0) | 2024.07.17 |
| Oracle ■ DML SELECT(1) (0) | 2024.07.10 |
| Oracle ■ 데이터베이스 종류와 기초 (0) | 2024.07.09 |