◈ OBJECT(SEQUENCE)◈
• SEQUENCE
번호를 자동으로 증가시켜주는 역할을 수행하는 객체
일반적으로 회원 번호, 게시글 번호 등 식별자 역할을 하는 PRIMARY KEY에 자주 사용됨
• 표현법
CREATE SEQUENCE 시퀀스이름
START WITH 시작값
INCREMENT BY 증가값
MAXVALUE 최대값
MINVALUE 최소값
CYCLE/NOCYCLE
CACHE 바이트크기/NOCACHE

• 캐시 메모리
발생할 값들을 미리 생성하여 저장해 두고, 메모리 공간에 미리 생성된 값을 가져다가 사용하여
그때 그때 생성하여 사용하는 것 보다 속도가 빨라짐
시퀀스의 캐시 메모리 기본 값은 20Byte
• SEQUENCE
시퀀스 생성 및 테스트 테이블 생성

시퀀스명.nextval 을 입력하여 시퀀스 실행 가능

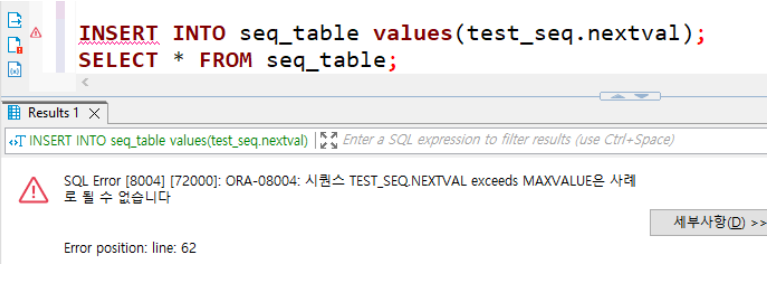
여러 번 사용하여 MAXVALUE에 다다르게 되면 ORA-08004 에러가 발생하며 이럴 경우
ALTER를 사용하여 MAXVALUE의 값을 늘려주어야 함
* 시퀀스의 값은 어느정도 여유있게 만드는것이 좋음
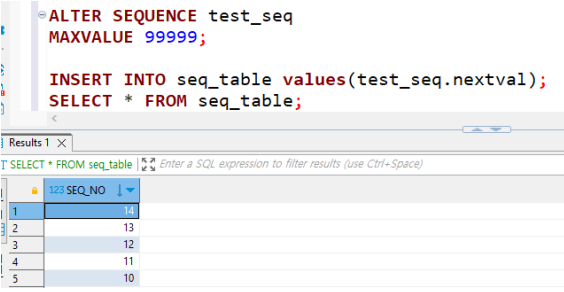
• 시퀀스 수정
아래의 쿼리를 사용하여 MAXVALUE의 값을 수정하고 이후 다시 시퀀스가 잘 실행되는지 확인하기
ALTER SEQUENCE 시퀀스명 MAXVALUE 수정할값;
◈ OBJECT(INDEX)◈
• INDEX
데이터가 많은 테이블에서 특정 컬럼에 대한 정렬 및 검색 성능을 향상시키기 위해 사용됨
• 참고
오라클에서는 PRIMARY KEY를 설정하면 자동으로 해당 컬럼에 대한 인덱스가 생성됨
* 자동 설정은 데이터베이스마다 다름
인덱스를 설정한 컬럼을 정렬하여 사본을 저장함

• INDEX 주의 사항
인덱스를 사용한다고 무조건 빨라지지 않으며 상황에 따라 오히려 인덱스를 사용함으로써
데이터 베이스의 성능에 악영향을 끼칠 수 있음
즉, 아래의 상황에서는 *풀 테이블 스캔이 더 좋은 퍼포먼스를 낼 수 있음
1. INSERT, UPDATE, DELETE 작업이 많은 컬럼
2. 크기가 작은 컬럼
3. 전체 데이터에 많은 양을 차지하는 컬럼의 값을 검색할 때
-> 일반적으로 전체 데이터 1~5% 미만의 데이터를 조회할 때 인덱스가 좋다고 함
• 풀 테이블 스캔(Full Table Scan)
테이블의 모든 데이터를 읽어가는 스캔 방식

• 이진 탐색 트리(Binary Search Tree)

• INDEX (이진탐색트리 기준)
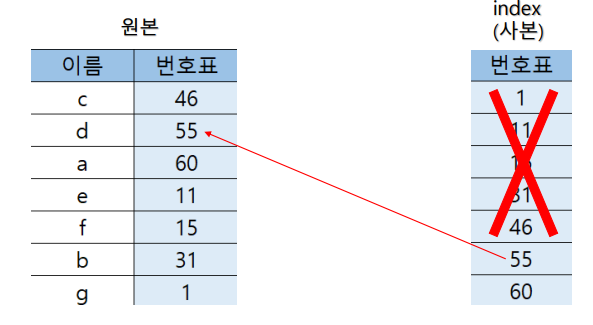
55번 데이터를 찾을 때

• INDEX (이진탐색트리 기준)
찾으려는 값이 31보다 크므로 그 아래의 데이터는 버리고 그 다음 31 ~ 60 사이의 값으로 이동

• INDEX (이진탐색트리 기준)
찾으려는 값이 46보다 크므로 그 아래의 데이터는 버리고 그 다음 46 ~ 60 사이의 값으로 이동

• INDEX (이진탐색트리 기준)
원하는 값을 찾았으므로 55번을 가진 원본 데이터로 포인터로 접근하여 원하는 데이터를 찾음
• B-Tree

• B+Tree

B-Tree보다 검색에 대한 성능이 더 좋기 때문에 최근의 데이터 베이스들과 검색 기능이 중요한 경우 B+Tree 형태로 인덱스를 많이 사용하는 추세
• 단일 인덱스 생성
CREATE INDEX 인덱스명 ON 테이블명(컬럼명)
• 인덱스 삭제
DROP INDEX 인덱스명
• 참고
인덱스를 수정하는 구문은 없으므로 수정을 위해서는 인덱스를 삭제하고 재생성 하는 과정이 필요함
오늘은 SEQUENCE와 INDEX에 대해 정리를 진행했다!
오라클관련 정리는 끝이났다.
다음 주제로는 정리해서 React,Servlet, Spring Framework에 대해 정리하여 업로드 예정이다.
그리고 별개로 프로젝트, 코딩테스트도 업로드할것이다
그럼 20000
'Back-End > Oracle' 카테고리의 다른 글
| Oracle ■ TCL COMMIT, ROLLBACK, SAVEPOINT (0) | 2024.08.07 |
|---|---|
| Oracle ■ DCL GRANT, REVOKE (0) | 2024.08.02 |
| Oracle ■ DDL ALTER, DROP (0) | 2024.07.29 |
| Oracle ■ 데이터베이스 정규화 (1) | 2024.07.26 |
| Oracle ■ CREATE (0) | 2024.07.25 |